
What is a Data Lake?
A Data Lake is a term that gets thrown around a fair amount, often in conjunction with big data. But what does it really mean?
At its core, its a central repository for storing unlimited amounts of data from many different sources that you can bring analytics to bear on top of to gain insights.
Do I even need a Data Lake?

Stadtbibliothek, Stuttgart, Deutschland - Photo by Tobias Fischer on Unsplash
It can be confusing with the evolving data landscape. It doesn’t mean you should throw out your current data approach though. Think of the data lake as an enhancement to existing systems. Don’t think of it as a replacement for datamarts or other data systems. Instead see it as the ability to collect and store data in various formats and schemas. to enhance what data drives downstream to those systems.
Why would you ever want to do this?
Today you may have a data warehouse that contains a single enterprise view of sales data. One challenge this could bring is that you can’t bring in more/different data sources. With a data lake you can. It allows the ability to store more data of differing types, more economically. With this you can start to explore it to gain better insights and understandings.
Difference between a Data Warehouse and a Data Lake
Pentaho CEO, James Dixon, is often credited for coining the term Data Lake and he defined the difference succinctly as so:
“If you think of a datamart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.”
If you need to package up your data into a clean, processed way then you will use a data warehouse. You can feed data warehouses from your data lake. You would do so to drive more specific reporting or views of the data to answer specific questions and generate key reports.
On the other hand, data in the data lake can be combined and explored in myriad different ways and can afford you greater insights, not just today but also in the future too. Its flexibility is a key trait that drives its value. It makes it easier for you to discover insights that previously you would not have been able to do. You can store data in your lake far cheaper than other types of store (for example, Azure Data Lake Store is about 8x cheaper vs Cosmos Db to store 1 TB of data).
There are some tradeoffs to think about though. Do you need fast performance? Are the users expecting the schema to be clear and make sense? If so, then you may need a downstream datamart to support these as an extension to your lake.
If we break it down to some of the big differences between a data warehouse and a data lake:
| Data Lake | Data Warehouse | |
|---|---|---|
| Data Type | Any - structure, unstructured etc. | Only supports structured, processed data |
| Cost | Relatively cheap for large data sizes | Expensive for large data sizes |
| Users | Data Scientists, Data Analysts | Business Intelligence workers, Business users |
| Maturity | Fairly new, still maturing | Been around several decades, fully mature |
| Processing | Schema on read, slower performing | Schema on write, higher performing |
Designing your Data Lake
When embarking on a data lake strategy, there are many things to think about. Below I cover a couple of key areas that are important to consider up front to avoid a data swamp emerging.

Think about how the Data Lake fits in
When working on your data lake strategy, think about how it will fit into your current structure. Treat the data lake as your central store which is fed from many inputs but also feeds many downstream systems.
Essentially a hub and spoke model with the hub being your data lake.
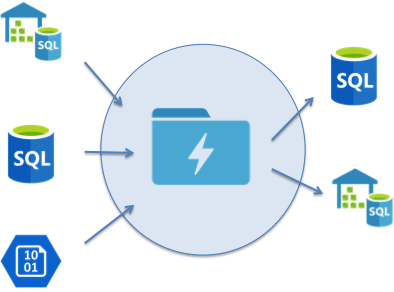
Data Lake Store Hub Architecture
Data from various sources will be ingested into your data lake store. These sources can be curated to some degree. You can then push views of this data into downstream systems for reporting or other purposes.
Partitioning
One of the first things you will want to think about is how you will partition your data as it lands in your lake. You will want to define a folder structure to put some control over the data as it comes in and how it flows through the lake.
At a high level define a structure like so:
raw_data/
processed_data/
exploration/
Raw Data
Imagine you are pulling in data from SAP systems and from some third party sales data in the form of CSV files. Perhaps you will create a structure like so under raw_data:
raw_data/
sap/
sales/
<region>/
<date>/
hh-filename.csv
third_party/
<vendor>/
<date>-filename.csv
An example could look like:
raw_data/
sap/
sales/
america-east/
2018-03-04/
09-extract.csv
10-extract.csv
third_party/
walmart/
2018-03-04-us_east_data.csv
Here we are landing raw data with very little up front processing - this is the Extract and Load part of ELT. We typically don’t want too many small files here so try to create partitions with files that are large enough to not cause performance issues when running analytics jobs over the top of them.
Processed Data
Now you will probably need to do some manipulation and processing of this raw data to create a view of it that can be used by your data teams or be picked up by automated systems to feed downstream datamarts:
processed_data/
sales_data/
<region>/
<date>-<filename>
To extend the example above this could be:
processed_data/
sales_data/
us-east/
2018-03-04-sales.csv
2018-03-05-sales.csv
This area will be the curated area of the data in your lake and will be the access point for most of your users of the lake. This is where data has been shaped from its raw form into a more understandable representation. This will be the area you will want to have governance around and will also be used to drive into downstream warehouses and datamarts.
Exploration Data
Finally, you will probably want to setup an exploratory area. This can be leveraged to explore the raw data in various ways without impacting existing flows. This would be an area to allow exploration in safety. In this area, you might create partitions per user.
If we put it all together the structure could look something like this:
raw_data/
sap/
sales/
<region>/
<date>/
hh-filename.csv
third_party/
<vendor>/
<date>-filename.csv
processed_data/
sales_data/
<region>/
<date>-<filename>
exploration/
<username>/
Data Lake Services in Azure
Azure has several great services to help you get started building out your data lake. Here are some of them:
| Area | Azure Service | Key Advantages |
|---|---|---|
| Storage | Azure Data Lake Store | Unlimited storage, optimized for analytics, enterprise ready |
| Analytics | Azure Data Lake Analytics | Pay per query. Query across all data in data lake store and other sources. |
| Analytics | Azure Databricks | Fast, easy, and collaborative Apache Spark-based analytics platform |
| Analytics | Azure HDInsight | Fully managed, full spectrum open-source analytics service for enterprises using Hadoop |
| Processing | Azure Data Factory | Build data pipelines and leverage various analytics throughout. |